Events
SALmon 2023 Workshop Information

Date: 24 March 2023
Time: 0900 - 1700
Location: KAIS 2020/2030
Hosted by: UBC Systopia
0830-0900 Room/Poster Setup
0900-0930 Breakfast
0930-1000 Mark Silberstein, Technion: Breaking the memory wall with computational cache: packet classification and beyond
As computer hardware evolves, processor compute capabilities scale much faster than memory performance and cache capacity. In our work we strive to leverage this trend to design faster computer systems by replacing memory-intensive data structures with computations.
We introduce a new algorithm for range matching which turns this memory-bound task into a compute-bound one, with the help of neural networks. Given a set of non-intersecting numerical ranges, the goal is to find the range that matches the input. Variants of this algorithm serve as building blocks in a variety of software and hardware systems, such as network switches and routers, storage controllers, DNA sequencing, and more. The key problem of conventional algorithms is that the index to perform matching grows too large, spilling out of fast caches, and constraining the number of ranges that can be handled efficiently. Our data structure, Range Query Recursive Model Index (RQRMI), allows compressing the index by up to two orders of magnitude by representing it as a neural network trained to predict the location of the correct range, thus replacing the index lookup with model inference.
In this talk I will show how we apply RQRMI to accelerate multi-field packet classification in a widely-used production software virtual switch Open VSwitch by over two orders of magnitude, while performing neural network inference on a CPU in the data plane. Our recent work demonstrates that RQRMI can offer significant benefits when implemented in hardware, i.e., to scale Longest Prefix Match in network routers to support millions of rules, or to reduce the SRAM requirements in SSDs with a more efficient Flash Translation Layer.
This talk is based on the published (SIGCOMM'20, NSDI'22) and an ongoing work led by my PhD student Alon Rashelbach in collaboration with Prof Ori Rottenstreich.
1000-1030 Gennady Pekhimenko, UofT: A Rise of Machine Learning Compilers
The recent popularity of deep neural networks (DNNs) has generated a lot of research interest in performing DNN-related computation efficiently. In this talk, we will demonstrate why machine learning compilers are critical to realize this vision. We will first look, briefly, at key existing optimization alternatives, and what their pros and cons are. I will then follow with a few of our recent works on machine learning compilers (DietCode, MLSys'22, Roller, OSDI'22, and Hidet, ASPLOS'23). At the end, he will show the performance and visualization tools we built in my group to understand, visualize, and optimize DNN models, and even predict their performance on different hardware (Skyline, UIST'20 and Habitat, ATC'21).
1030-1100 Break
1100-1130 Anand Jayarajan, UofT: TiLT: A Time-Centric Approach for Stream Query Optimization and Parallelization
Stream processing engines (SPEs) are widely used for large scale streaming analytics over unbounded time-ordered data streams. Modern day streaming analytics applications exhibit diverse compute characteristics and demand strict latency and throughput requirements. Over the years, there has been significant attention in building hardware-efficient stream processing engines (SPEs) that support several query optimization, parallelization, and execution strategies to meet the performance requirements of large scale streaming analytics applications. However, in this work, we observe that these strategies often fail to generalize well on many real-world streaming analytics applications due to several inherent design limitations of current SPEs. We further argue that these limitations stem from the shortcomings of the fundamental design choices and the query representation model followed in modern SPEs. To address these challenges, we first propose TiLT, a novel intermediate representation (IR) that offers a highly expressive temporal query language amenable to effective query optimization and parallelization strategies. We subsequently build a compiler backend for TiLT that applies such optimizations on streaming queries and generates hardware-efficient code to achieve high performance on multi-core stream query executions. We demonstrate that TiLT achieves up to 326x (20.49x on average) higher throughput compared to state-of-the-art SPEs (e.g., Trill) across eight real-world streaming analytics applications. TiLT source code is available at https://github.com/ampersand-projects/tilt.git.
1130-1200 Don Porter, UNC: The OS Can Shoulder More Virtual Memory Complexity
Virtual memory is foundational in modern computer systems, and its performance is cracking under the demands of applications with larger working sets, larger and more complex physical memories, and growing security demands. This talk will describe two performance challenges in modern virtual memory systems, and show how the OS can accept more of the burden for virtual memory performance from the hardware, thereby improving performance.
First, we describe Mosaic pages, a project that increases TLB reach without requiring physical contiguity and the associated costs of defragmentation. Data-hungry applications are increasingly bottlenecked on the TLB. Many solutions to this problem rely on physical contiguity to increase TLB reach, which comes at the cost of defragmenting memory; the costs of defragmentation can be high enough to easily nullify the gains from TLB reach. In the Mosaic project, we instead explore restricting where a virtual address can be mapped to improve TLB reach---by compressing physical addresses and packing multiple, discrete translations into one TLB entry. Mosaic is built upon a hashing scheme with unique properties, designed for virtual memory. In simulation, Mosaic reduces TLB misses by up to 81%. Moreover, the restrictions on memory mappings do not harm performance.
Second, we describe early experiences in the Gramine (formerly Graphene) library OS with Intel's Enclave Dynamic Memory Management (EDMM), a feature of SGX version 2 that can enables common optimizations such as demand faulting pages into an address space. Although EDMM dramatically reduces loading time of an enclave, it harms overall runtime when used in a straightforward manner. This talk will explain the reasons for these runtime overheads, and optimizations that eliminate these runtime overheads while retaining the loading time and functional benefits of EDMM.
1200-1300 Lunch
1300-1330 Martin Maas, Google Brain: Towards a General ML for Systems Methodology
Machine learning has the potential to significantly improve computer systems. While recent research in this area has shown great promise, not all problems are equally well-suited for applying ML techniques, and some remaining challenges have prevented wider adoption of ML in systems. In this talk, I will introduce a taxonomy to classify machine learning for systems approaches, discuss how to identify cases that are a good fit for machine learning, and lay out a longer-term vision of how we can improve systems using ML techniques, ranging from computer architecture to language runtimes. I will then cover two specific applications of ML for Systems: learning-based memory allocation for C++ and ML for storage systems.
1330-1400 Justin Funston, Futurewei: Chogori: µsec-Scale Distributed Transactions
Chogori is a distributed and fast key-value storage system that provides strictly serializable transactions. This talk will cover the high-level architecture and MVCC-based transaction protocol which we designed to minimize network round-trips, and it will cover the systems-level optimizations needed for high performance. Chogori achieves a TPC-C average transaction latency of 500 µsec and a simple read transaction throughput of 20,000 per second per core. RDMA messaging, per-core partitioning and network addressing, and a modern asynchronous programming model all contribute to this performance result. Lastly I will discuss some open research topics we encountered while developing Chogori.
1400-1430 Tianzheng Wang, SFU: Asynchronous Data Movement for Modern Transactional Data Systems
Data movement is often a significant overhead in data processing tasks. Going through the storage hierarchy, data is typically fetched from the lowest storage tier to CPU caches on-demand, often using synchronous primitives such as memory loads and traditional POSIX interfaces, causing various stalls and delays on the critical path. These data movement operations must also be conducted with transactional semantics, making traditional techniques like software prefetching hard to be adopted by existing systems. In this talk, we will introduce our on-going effort on the CoroBase project (https://github.com/sfu-dis/corobase), which leverages asynchronous data movement primitives and recent lightweight coroutines (e.g., stackless coroutines in C++20), to hide data movement latencies across the storage hierarchy and thus improve transaction and query performance. Especially, we emphasize the effort to make these algorithms work in an end-to-end database engine, which requires considerations in aspects beyond pure performance, such as programmability and backward compatibility. We will also highlight our current progress and a few promising future directions.
1430-1500 Tea/Coffee Break
1500-1700 Poster Session
Accelerating Recommender Model Inference Using Processing-In-Memory
Niloofar Zarif, Justin Wong, Alexandra Fedorova
AfterImage: Leaking Control Flow Data and Tracking Load Operations via the Hardware Prefetcher
Lingfeng Pei, Yun Chen, Trevor E. Carlson
Anomaly Detection in Complex Networks
Ali Behrouz, Sadaf Sadeghian, Margo Seltzer
Anticipating and Eliminating Redundant Computations in Accelerated Sparse Training
Jonathan Lew, Yunpeng Liu, Wenyi Gong, Negar Goli, R David Evans, and Tor M Aamodt
Black-Box Privacy Auditing of Machine Learning Pipelines
Mishaal Kazmi, Alireza Akbari, Hadrien Laurette, Sébastien Gambs, Mathias Lécuyer
CHERI-picking: Leveraging capability hardware for pre-fetching
Shaurya Patel, Sidhartha Agrawal, Alexandra Fedorova, Margo Seltzer
Compiling Distributed Systems with PGo
Finn Hackett, Shayan Hosseini, Renato Costa, Matthew Do, Ivan Beschastnikh
ConstSpec: Mitigating Cache-based Spectre Attacks via Fine-Grained Constant-Time Accesses
Arash Pashrashid
DP-Adam: Correcting DP Bias in Adam’s Second Moment Estimation
Qiaoyue Tang, Mathias Lécuyer
Enhanced Unstructured Data Search
William Anthony Mason
Evaluating Partial Memory Traces for Page Temperature Detection
Victor Garvalov, Shaurya Patel, Alexandra Fedorova
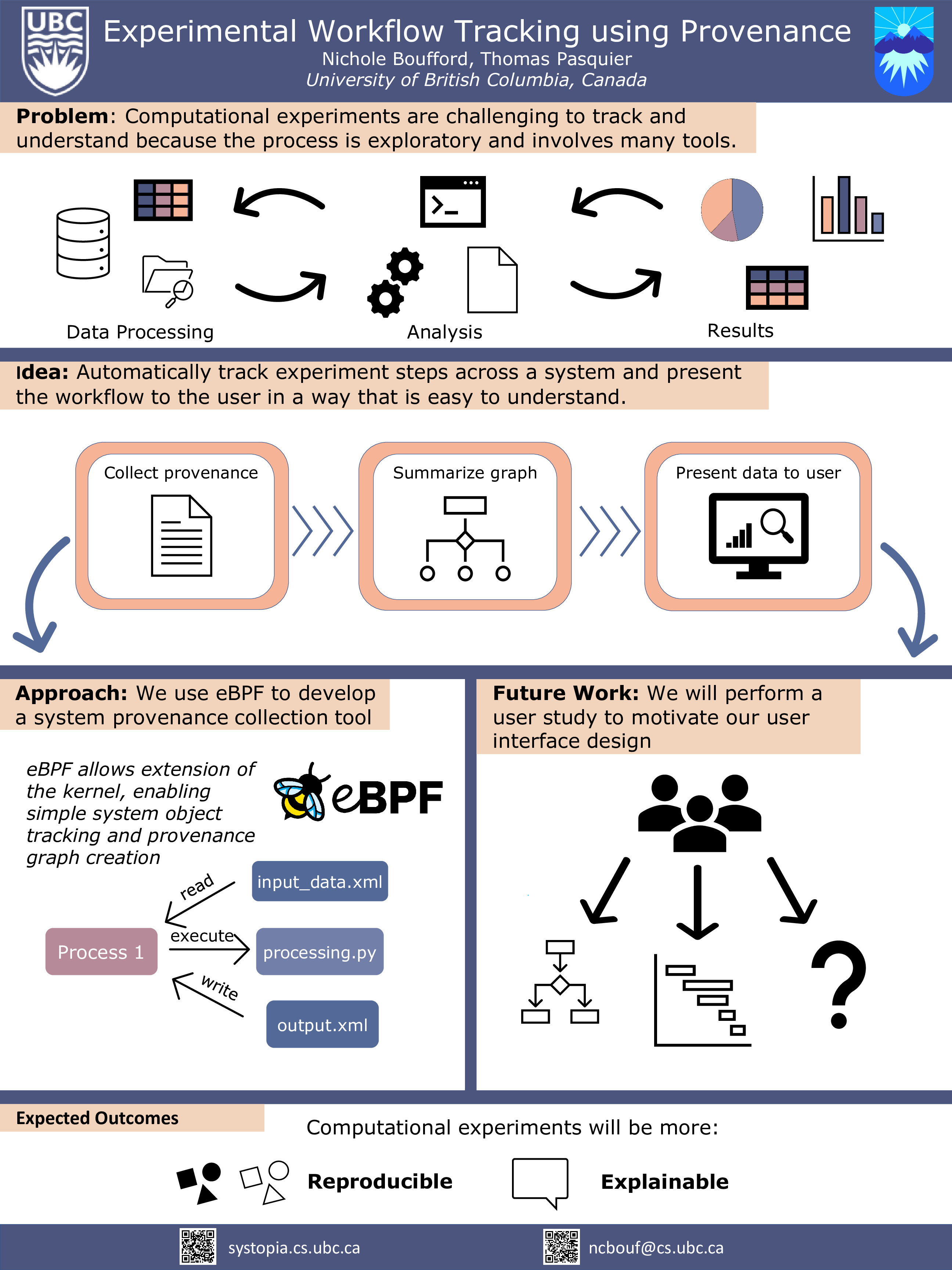
Experimental Workflow Tracking using Provenance
Nichole Boufford, Thomas Pasquier
FeMux: The Last “Leg” of Serverless Workload Forecasting
Nima Nasiri, Nalin Munshi
Flexograph: Storing and Analyzing Large Graphs
Puneet Mehrotra, Haotian Gong, Margo Seltzer
FlowCache: Accelerating Network Functions using Programmable Switches
Swati Goswami, Jacob Nelson, Dan Ports, Margo Seltzer
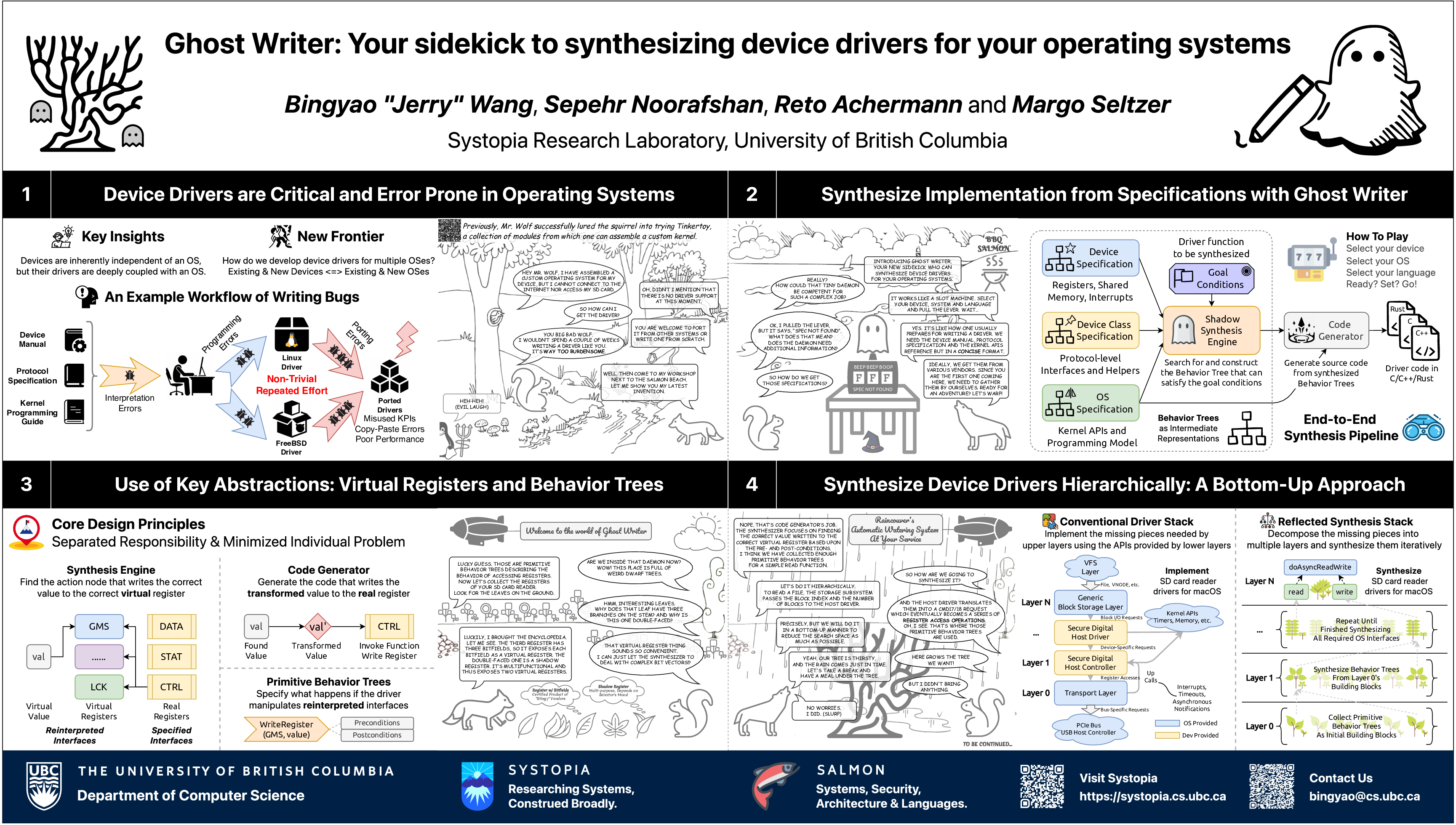
Ghost Writer: Your sidekick to synthesizing device drivers for your operating systems
Bingyao "Jerry" Wang, Sepehr Noorafshan, Reto Achermann and Margo Selzer
GlueFL: Reconciling Client Sampling and Model Masking for Bandwidth Efficient Federated Learning
Shiqi He, Qifan Yan, Feijie Wu, Lanjun Wang, Mathias Lécuyer, Ivan Beschastnikh
Latency and Cost Aware Offloading of Functions from Serverless Platforms
Ghazal Sadeghian, Mohamed Elsakhawy, Mohanna Shahrad, Joe Hattori, Mohammad Shahrad
MERIT: Integrated Reproducibility with Self-describing Machine Learning Models
Joseph Wonsil, Jack Sullivan, Margo Seltzer, and Adam Pocock
Mitigating Network Side Channels: From Internet to Interconnects
Amir Sabzi, Rut Vora, Swati Goswami, Margo Seltzer, Mathias Lécuyer, and Aastha Mehta
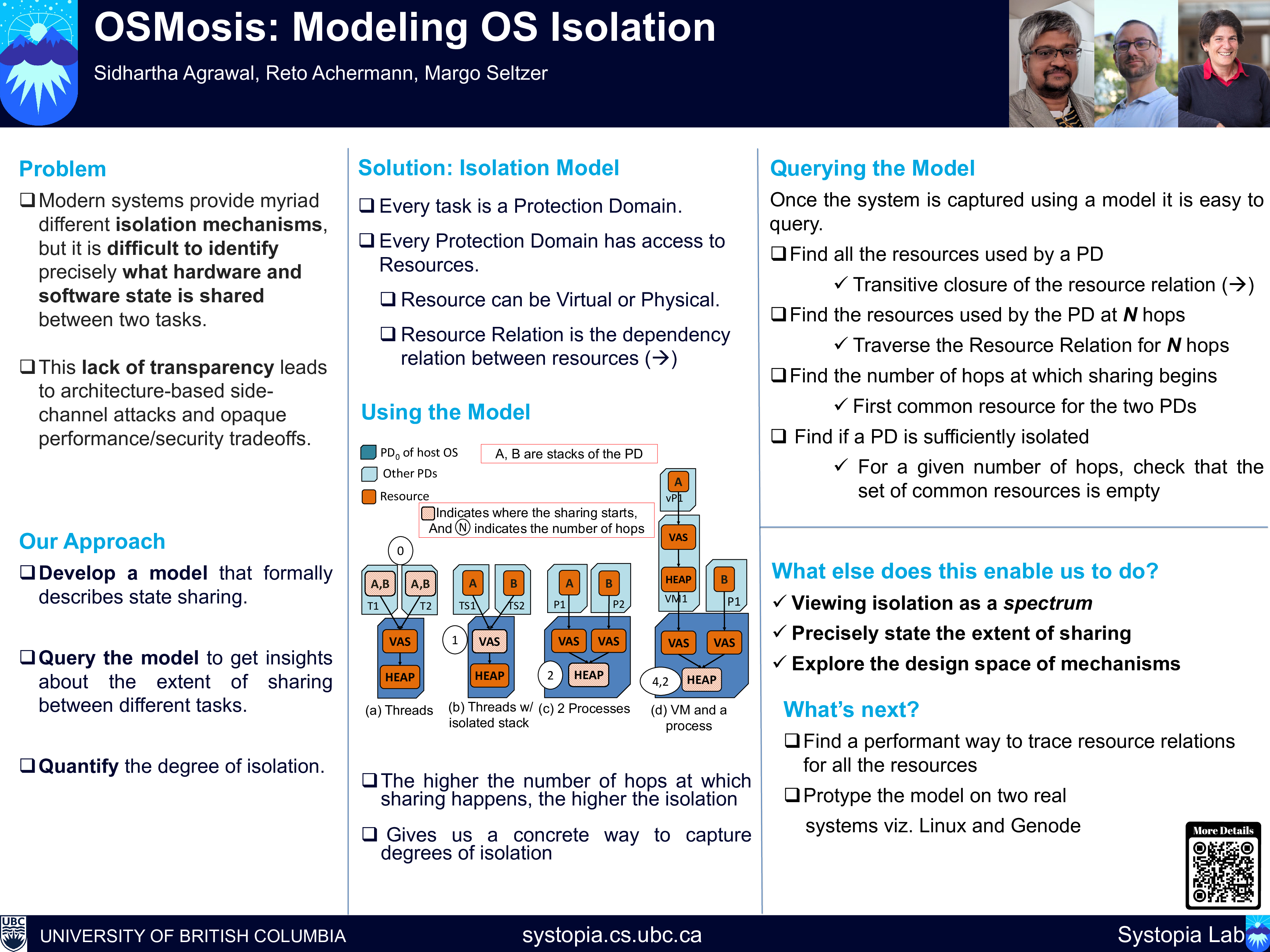
OSMosis: Modeling OS Isolation
Sidhartha Agrawal, Reto Achermann, Margo Seltzer
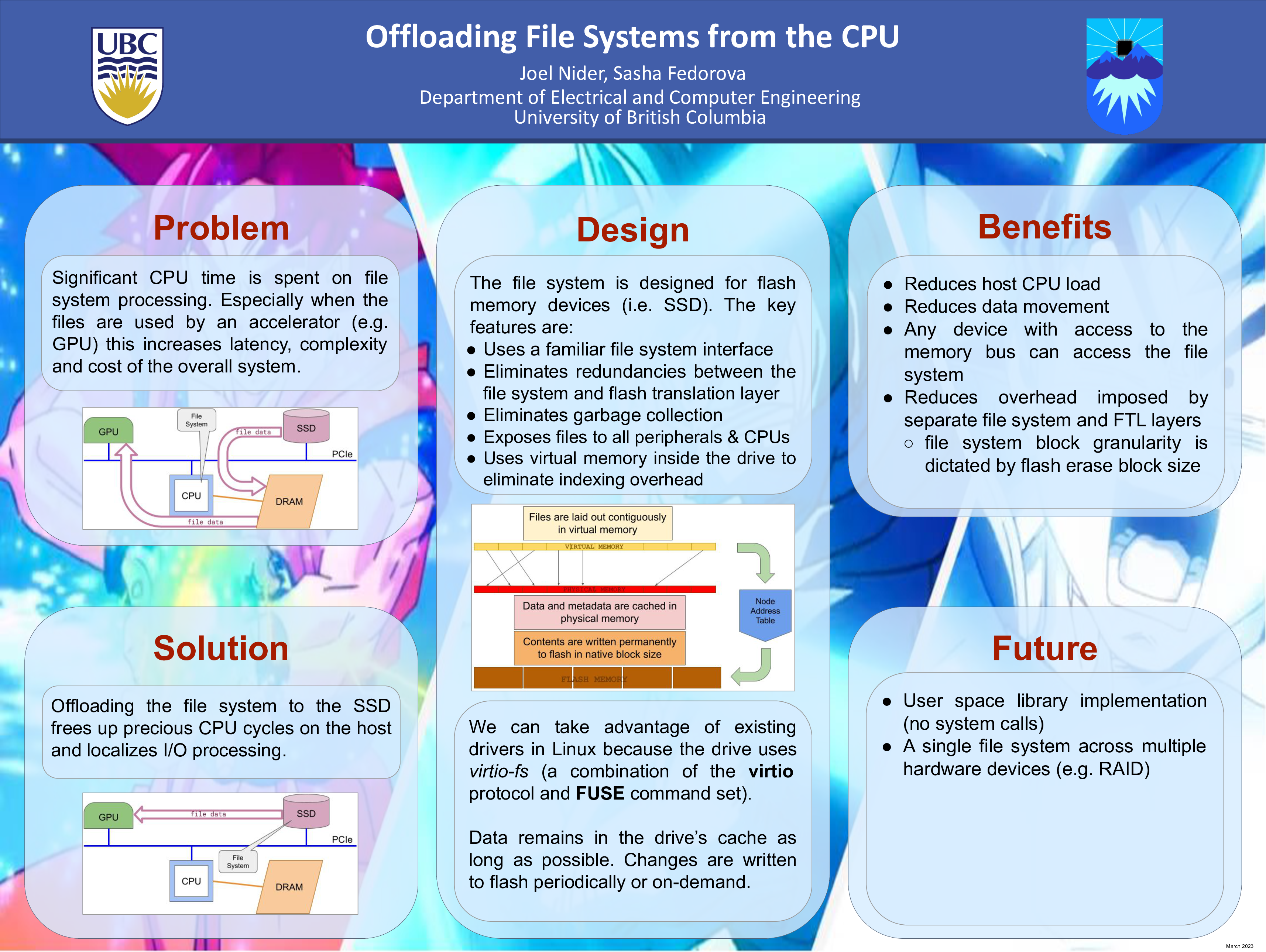
Offloading File Systems from the CPU
Joel Nider, Alexandra Fedorova
PARADISE: Mitigating Power Attacks through Fine-Grained Instruction Reordering
Yun Chen
PowerPrint: Fine-Grained Intrusion Detection Through Power Analysis for Safety-Critical Cyber-Physical Systems
Maryam R. Aliabadi
Processing-in-memory for Column-store Workloads
Niloofar Gharavi, Alexandra Fedorova
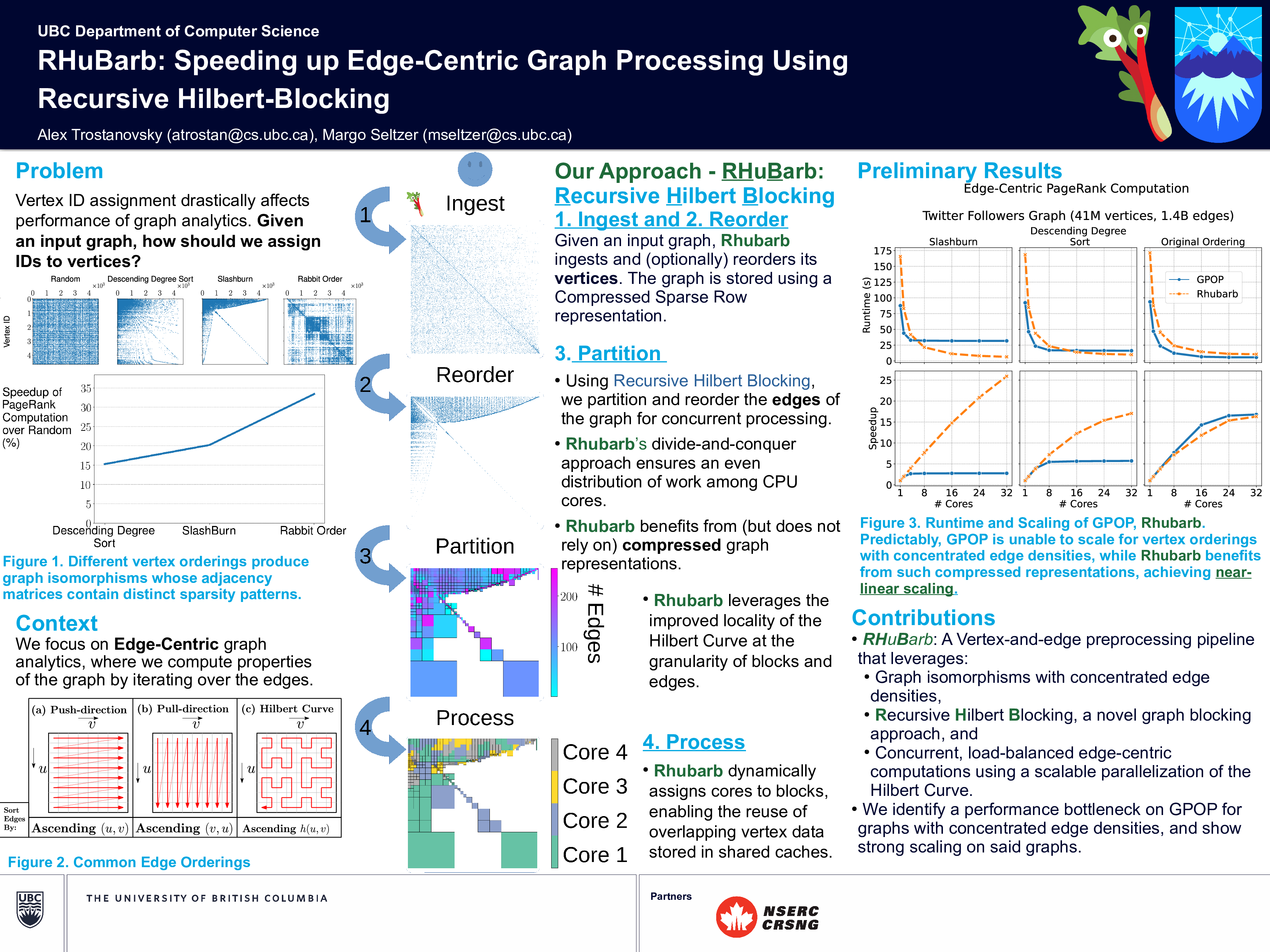
RHuBarb: Speeding up Edge-Centric Graph Processing Using Recursive Hilbert-Blocking
Alex Trostanovsky, Margo Seltzer
Reinforcement Learning with Work Duplication for Load Balancing in Elasticsearch
Haley Li, Mathias Lécuyer
Right Place, Write Architecture for SMR drives
Surbhi Palande, Alexandra Fedorova, Margo Seltzer
Secure Kernel Extensibility With eBPF
Soo Yee Lim, Xuechun Cao, Thomas Pasquier
Securing Self-Driving Laboratories: A Collaboration between Computer Science and Chemistry
Zainab Saeed Wattoo, Petal Vitis, Arpan Gujarati, Maryam Aliabadi, Sean Clark, Noah Depner, Xiaoman Liu, Parisa Shiri, Amee Trivedi, Ivory Zhang, Ruizhe Zhu, Jason Hein, and Margo Seltzer
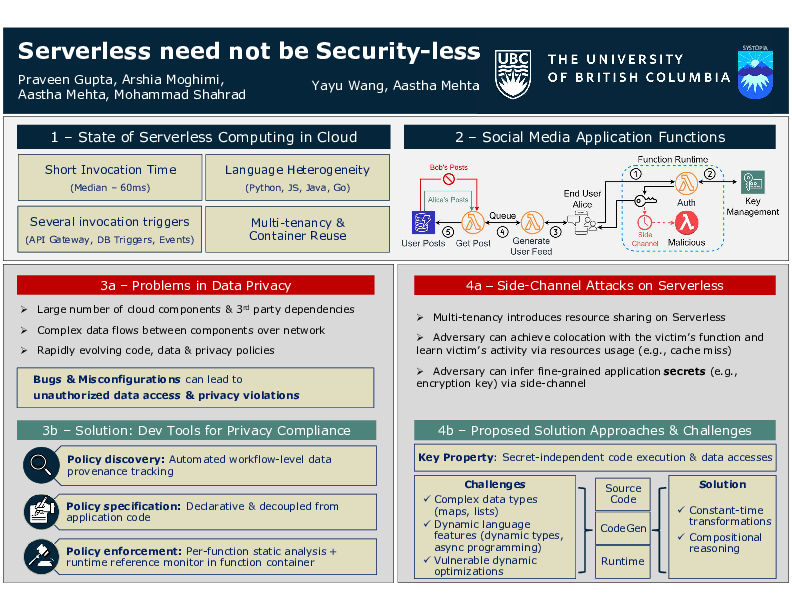
Serverless need not be Security-less
Praveen Gupta, Arshia Moghimi, Aastha Mehta, Mohammad Shahrad, Yayu Wang
Shellac: compiler sketching with rewrite rule synthesis
Christopher Chen, Margo Seltzer, and Mark Greenstreet
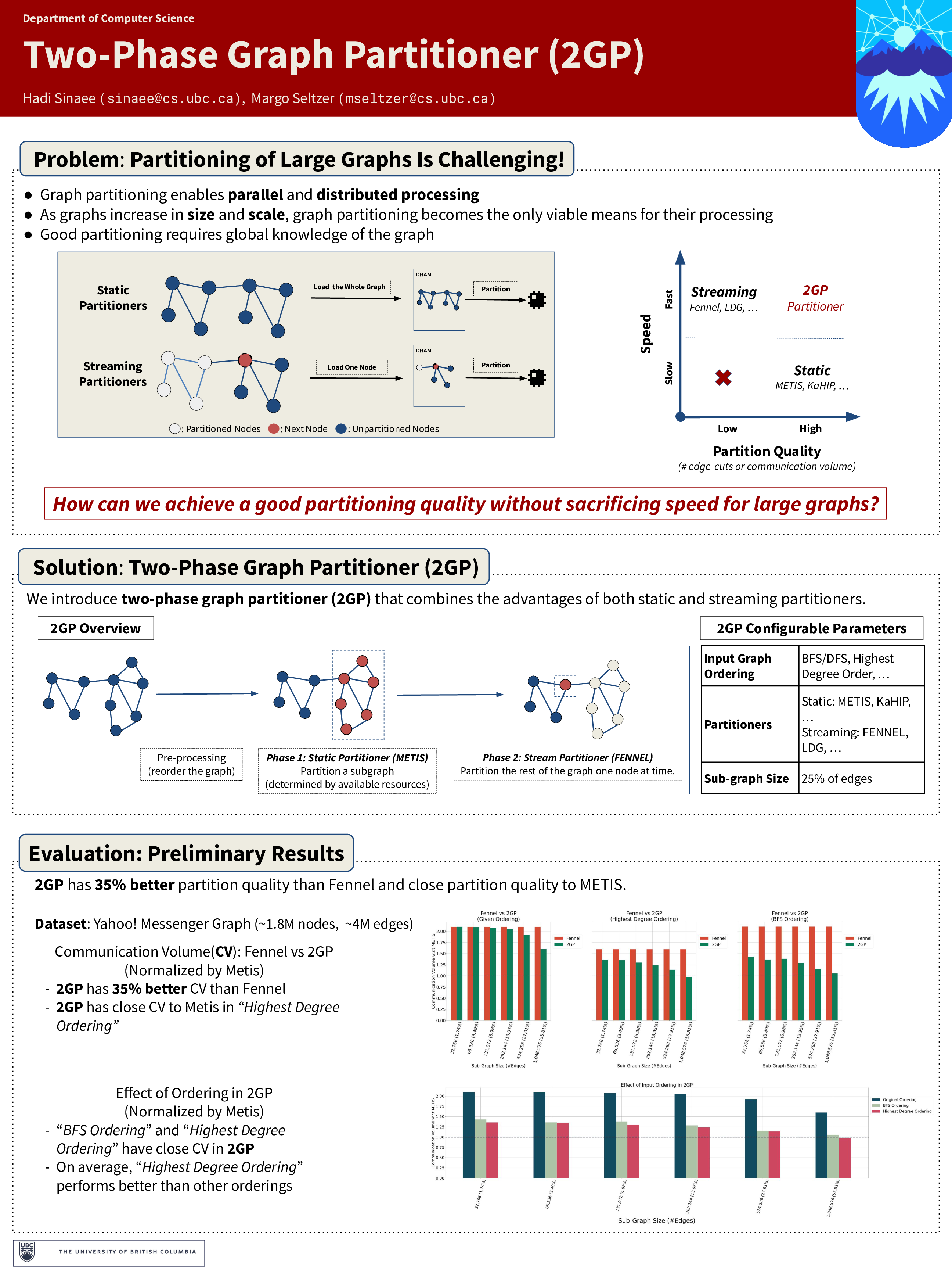
Two-Phase Graph Partitioner (2GP)
Hadi Sinaee, Margo Seltzer
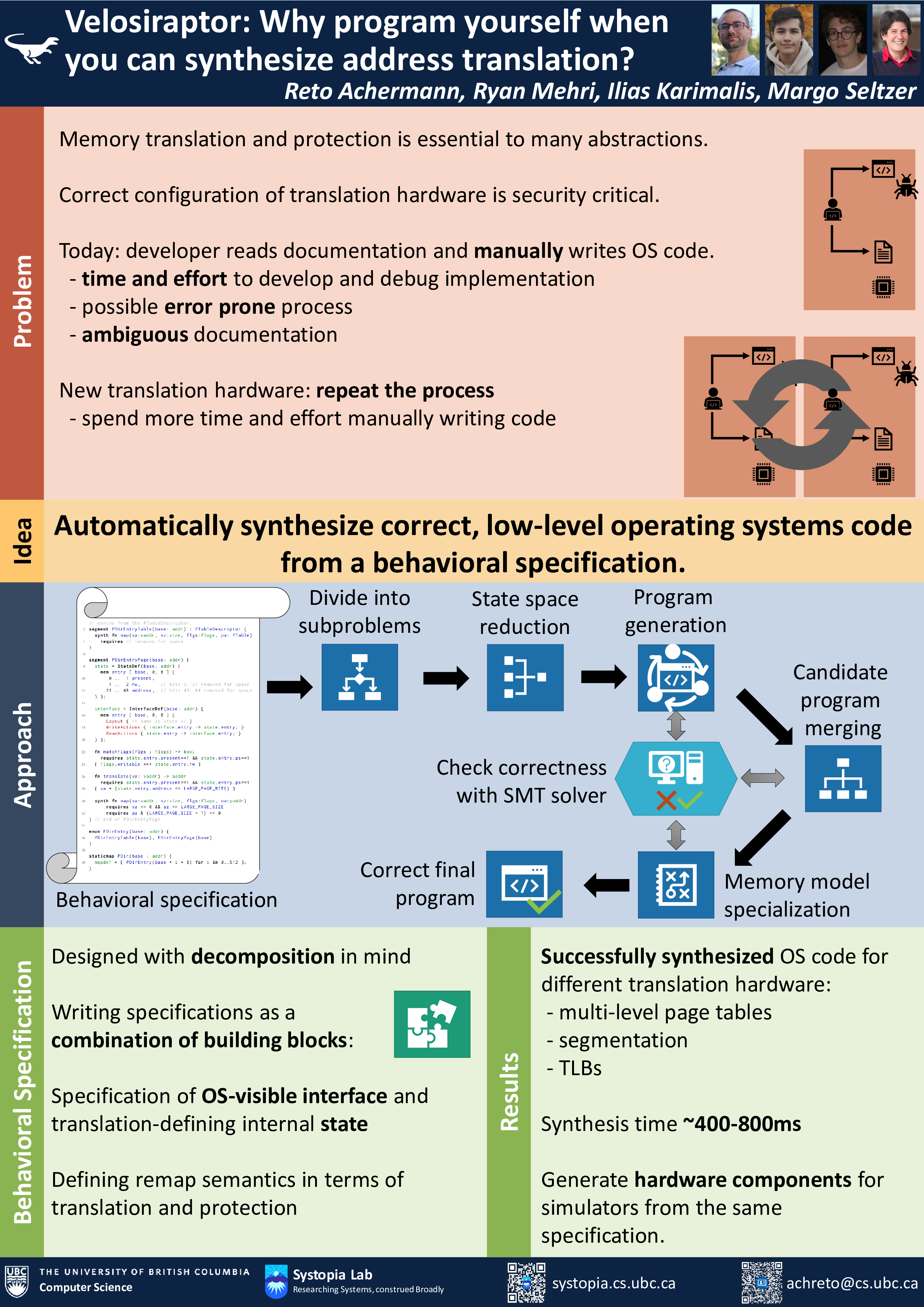
Velosiraptor: Why program yourself when you can synthesize address translation?
Reto Achermann, Ryan Mehri, Ilias Karimalis, Margo Seltzer
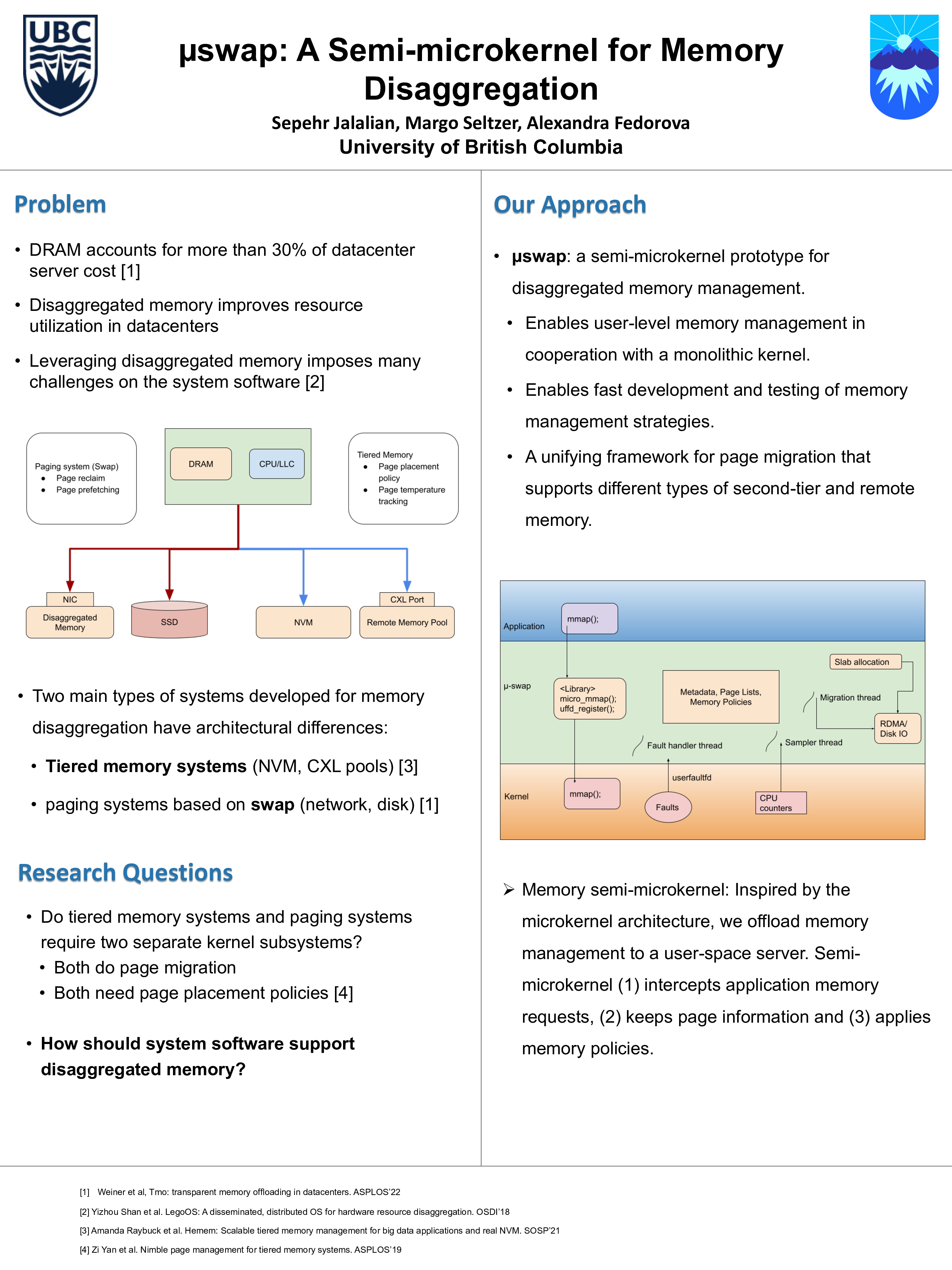
μswap: A Semi-microkernel for Memory Disaggregation
Sepehr Jalalian, Margo Seltzer, Alexandra Fedorova
Photos

























Posters















Systopia lab is supported by a number of government and industrial sources, including Cisco Systems, the Communications Security Establishment Canada, Intel Research, the National Sciences and Engineering Research Council of Canada (NSERC), Network Appliance, Office of the Privacy Commissioner of Canada, and the National Science Foundation (NSF).